ACM SIGCHI Conference on Human Factors in Computing Systems 2024
AQuA
Automated Question-Answering in Software Tutorial Videos with Visual Anchors
Abstract
Tutorial videos are a popular help source for learning feature-rich software. However, getting quick answers to questions about tutorial videos is difficult. We present an automated approach for responding to tutorial questions. By analyzing 633 questions found in 5,944 video comments, we identified different question types and observed that users frequently described parts of the video in questions. We then asked participants (N=24) to watch tutorial videos and ask questions while annotating the video with relevant visual anchors. Most visual anchors referred to UI elements and the application workspace. Based on these insights, we built AQuA, a pipeline that generates useful answers to questions with visual anchors. We demonstrate this for Fusion 360, showing that we can recognize UI elements in visual anchors and generate answers using GPT-4 augmented with that visual information and software documentation. An evaluation study (N=16) demonstrates that our approach provides better answers than baseline methods.
Download publication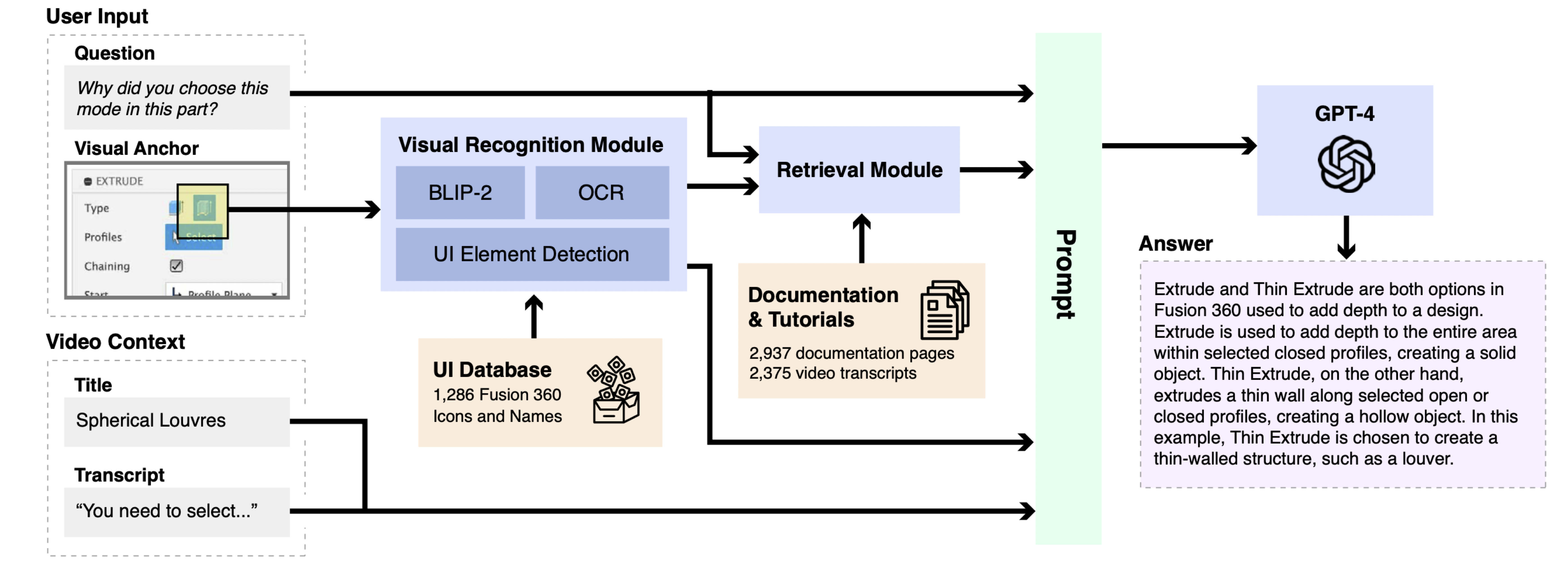
The AQuA question-answer pipeline generates accurate answers to questions about software tutorial videos with visual anchors. It achieves this by recognizing visual UI elements, retrieving relevant software documentation and tutorial videos, extracting the video context, and then generating an answer based on this by leveraging the Large Language Model GPT-4.
Associated Researchers
Saelyne Yang
Korea Advanced Institute of Science & Technology (KAIST)
Related Stories
2024
TimeTunnel: Integrating Spatial and Temporal Motion Editing for Character Animation in Virtual RealityThis research provides an approachable editing experience by…
2023
Task-Centric Application Switching: How and Why Knowledge Workers Switch Software Applications for a Single TaskThis research studies task-centric application switching and…
2023
Identifying Visualization Opportunities to Help Architects Manage the Complexity of Building CodesInteractive visualizations have promising potential to aid design…
2023
3DALL-E: Integrating Text-to-Image AI in 3D Design Workflows3DALL-E integrated three large AI models within Fusion 360 to explore…
Get in touch
Something pique your interest? Get in touch if you’d like to learn more about Autodesk Research, our projects, people, and potential collaboration opportunities.
Contact us